
NVIDIA BERT推理解决方案Faster Transformer开源啦
2019-07-15 20:00
 分享到微信
分享到微信
 分享到微博
分享到微博
Faster Transformer是一个基于CUDA和cuBLAS的Transformer Encoder前向计算实现,其优越的性能将助力于多种BERT的应用场景。
2017年12月Google在论文“Attention is All You Need”[1] 中首次提出了Transformer,将其作为一种通用高效的特征抽取器。至今,Transformer已经被多种NLP模型采用,比如BERT[2]以及上月发布重刷其记录的XLNet[3],这些模型在多项NLP任务中都有突出表现。在NLP之外, TTS,ASR等领域也在逐步采用Transformer。可以预见,Transformer这个简洁有效的网络结构会像CNN和RNN一样被广泛采用。虽然Transformer在多种场景下都有优秀的表现,但是在推理部署阶段,其计算性能却受到了巨大的挑战:以BERT为原型的多层Transformer模型,其性能常常难以满足在线业务对于低延迟(保证服务质量)和高吞吐(考虑成本)的要求。以BERT-BASE为例,超过90%的计算时间消耗在12层Transformer的前向计算上。因此,一个高效的Transformer 前向计算方案,既可以为在线业务带来降本增效的作用,也有利于以Transformer结构为核心的各类网络在更多实际工业场景中落地。本文将介绍NVIDIA GPU计算专家团队针对Transformer推理提出的性能优化方案:Faster Transformer。
Faster Transformer是一个BERT Transformer 单层前向计算的高效实现,其代码简洁明了,后续可以通过简单修改支持多种Transformer结构。目前优化集中在编码器(encoder)的前向计算(解码器decoder开发在后续特性规划中)。底层由CUDA和cuBLAS实现,支持FP16和FP32两种计算模式,其中FP16可以充分利用Volta和Turing架构GPU上的Tensor Core计算单元。
Faster Transformer共接收4个输入参数。首先是attention head的数量以及每个head的维度。这两个参数是决定Transformer网络结构的关键参数。这两个参数的动态传入,可以保证Faster Transformer既支持标准的BERT-BASE(12 head x 64维),也支持裁剪过的模型(例如,4 head x 32维),或者其他各式专门定制化的模型。其余两个参数是Batch Size 和句子最大长度。出于性能考虑,目前句子最大长度固定为最常用的32,64 和128三种,未来会支持任意长度。Faster Transformer对外提供C++ API,TensorFlow OP 接口,以及TensorRT [4]插件,并提供了相应的示例,用以支持用户将其集成到不同的线上应用代码中。
Faster Transformer目前已经开源,欢迎扫描下方二维码,获取项目全部源代码,最新的性能数据以及支持的特性。欢迎大家前往使用,加星和反馈:

性能数据
Faster Transformer在不同的应用场景下都有着突出的表现。我们在这里测试了不同生产环境下Faster Transformer前向计算的执行时间以及与TensorFlow XLA的性能比较。测试环境如表1所示:
表1. 性能数据测试环境(本地服务器)

首先针对线上QPS较低的业务(例如问答),我们将batch size设置为1,测试了BERT标准模型在不同的句子长度下,12层Transformer在P4和T4上的性能。由于这种场景下TensorFlow的性能非常依赖于CPU,因此这里不予列出。
表2. 小batch size情况下Faster Transformer的性能

接着我们来观察Faster Transformer在搜索或者广告推荐等大batch size场景下的加速效果。表3和表4分别测试了固定句子长度为32,标准模型(12 head x 64维)和裁剪模型(4 head x 32维)在不同batch size下,12层Transformer 在V100上使用了FP16计算精度的性能。
表3. 标准模型不同Batch Size下TensorFlow XLA和Faster Transformer在V100上的性能对比

表4. 裁剪模型不同Batch Size下TensorFlow XLA和Faster Transformer在V100上的性能对比
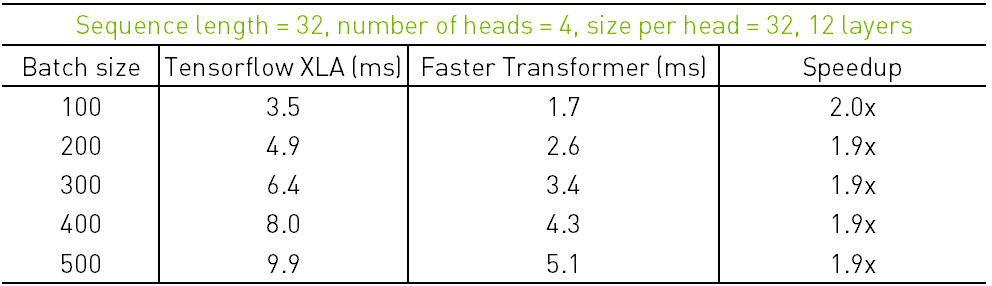
可以看出,在标准模型和裁剪模型上,Faster Transformer都有很好的加速效果。
使用方法
Faster Transformer提供了TensorFlow OP ,C++ API和TensorRT Plugin 三种接口。
在TensorFlow中
使用Faster Transformer
在TensorFlow中使用Faster Transformer最为简单。只需要先import .so文件,然后在代码段中添加对Faster Transformer OP的调用即可。具体代码如下所示。
# import op
transformer_op_module = tf.load_op_library(os.path.join(\'../../build/lib/libtf_transformer.so\'))
...
def fast_transformer_model_trans(...)
...
# original code
...
layer_output = layer_norm(layer_output + attention_output)
# calling faster transformer op
trainable_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=tf.get_variable_scope().name)
layer_output = transformer_op_module.bert_transformer(
layer_input,
layer_input,
trainable_vars[0], trainable_vars[2], trainable_vars[4], trainable_vars[1], trainable_vars[3], trainable_vars[5],
attention_mask,
trainable_vars[6], trainable_vars[7], trainable_vars[8], trainable_vars[9], trainable_vars[10], trainable_vars[11],
trainable_vars[12], trainable_vars[13], trainable_vars[14], trainable_vars[15],
batch_size=batch_size, from_seq_len=seq_length, to_seq_len=seq_length, head_num=num_attention_heads, size_per_head=attention_head_size)
# original code
...
all_layer_outputs.append(layer_output)
...
使用C++ API或者TensorRT
调用Faster Transformer
考虑到封装成TensorFlow OP会引入一些额外的开销,我们更建议用户直接使用C++ API或者TensorRT Plugin的方式去集成。目前这两种方式不支持直接解析训练好的模型。Transformer层所需要的weights参数,需要用户手动从训练好的模型中导出。调用方式相对简单,将导出的weights赋值给参数结构体,创建相应的对象,调用initialize或者build_engine函数初始化对象。运行时,每次调用forward或者do_inference即可。具体代码如下所示。
/* C++ interface */
typedef BertEncoderTransformerTraits
fastertransformer::Allocator
EncoderInitParam<__half> encoder_param; //init param here
encoder_param.from_tensor = d_from_tensor;
...
BertEncoderTransformer
BertEncoderTransformer
encoder_transformer_->initialize(encoder_param);
encoder_transformer_->forward();
/* TensorRT Plugin */
std::vector
/* push all weight pointers into the vector params*/
TRT_Transformer
trt_transformer->build_engine(params);
trt_transformer->do_inference(batch_size, h_from_tensor, h_attr_mask, h_transformer_out, stream);
优化原理
在深入了解Faster Transformer的优化原理之前,我们先来看下TensorFlow的实现情况。图1是TensorFlow在默认计算模式(不使用XLA优化)下的时间线片段。

图1. TensorFlow计算GELU的时间线
其中,黄色矩形框中对应的是激活函数GELU。可以看到,在TensorFlow中,这个函数是通过8个类似Pow,Add,和Tanh等基本OP来实现的。Layer Normalization 操作也是类似的情况(图2)。

图2. TensorFlow计算Layer Normalization的时间线
在TensorFlow中,每一个基本OP都会对应一次GPU kernel的调用,和多次显存读写,这些都会增加大量额外的开销。TensorFlow XLA可以在一定程度上缓解这个问题,它会对一些基本的OP进行合并,以减少GPU kernel的调度和显存读写。但在大多数情况下,XLA依然无法达到最优的性能,特别是对于BERT这种计算密集的情况,任何性能的提升都将节省巨量的计算资源。
如我们前面提到的,OP融合可以降低GPU调度和显存读写,进而提升性能。出于性能最大化的考虑,在Faster Transformer内部,我们将除矩阵乘法以外的所有kernel都进行了尽可能的融合,单层Transformer的计算流程如下图所示:
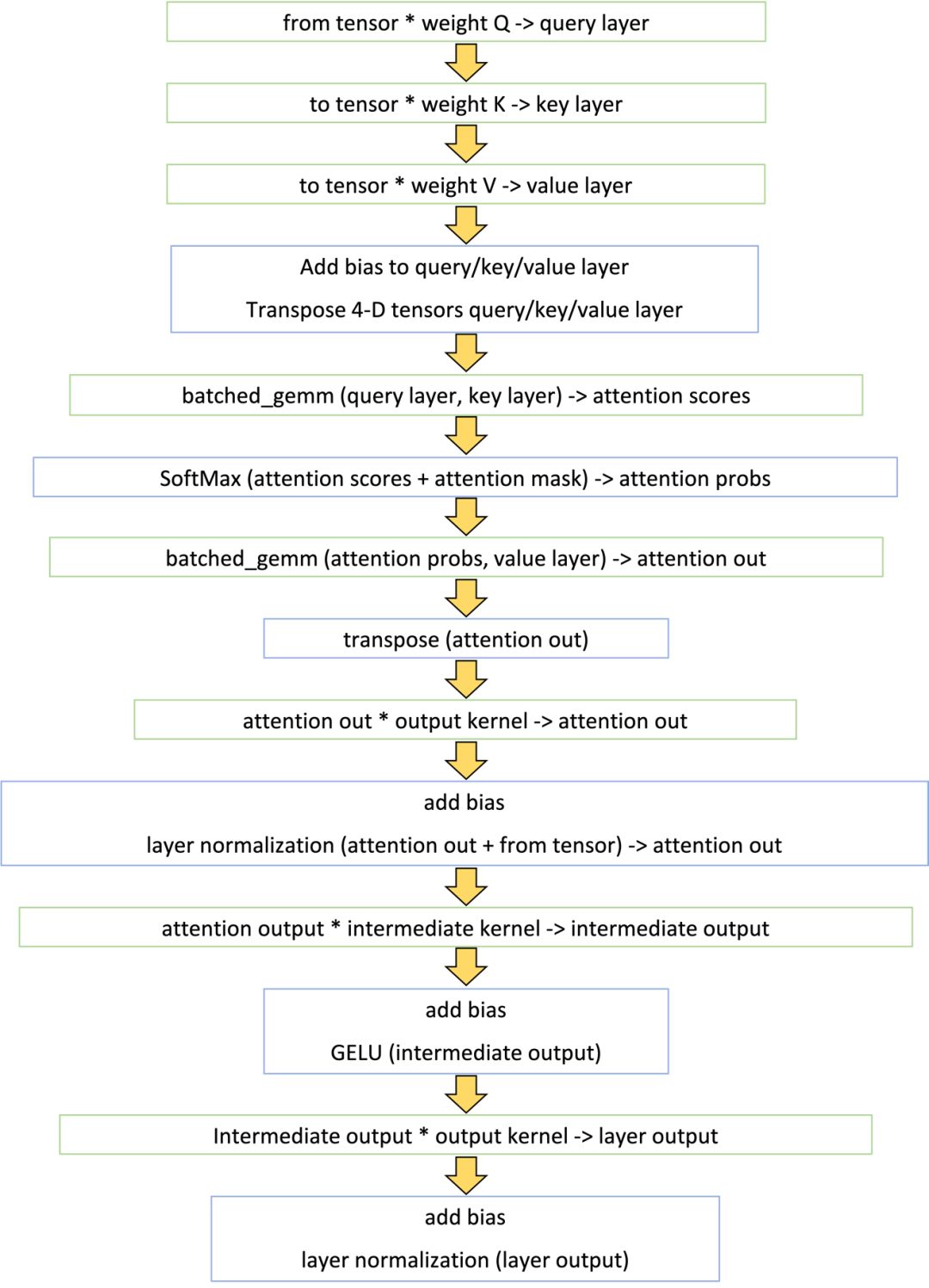
图3. BERT中Transformer Layer 的计算流程图
如图3所示,Faster Transformer只用了14个kernel就完成了原来将近60个kernel的计算逻辑。这其中,8个kernel是通过调用cuBLAS接口计算矩阵乘法(绿色框),其余6个是自定义kernel (蓝色框)。
针对batch size比较小的场景(例如问答,TTS等),简单的融合后,基本上就可以达到很好的性能。这类场景下,TensorFlow原生实现的最大瓶颈就在于频繁的kernel launch,融合后大大降低了launch的开销,因此可以比较轻易地获得很好的加速效果。
针对大batch的场景,我们需要对矩阵乘法和所有的自定义kernel做精细的调优,才能达到很好的加速效果。我们从矩阵乘法算法选择,非矩阵乘法操作的参数配置,SoftMax多版本实现,以及数据结构类型等几个方面对大batch的情况进行了专门的调优。
首先针对矩阵乘法,在调用cuBLAS的接口时,可以指定性能最优的算法。特别是针对Volta和Turing架构的GPU,使用Tensor Core进行半精度计算时,当精度满足需求的情况下,累加器也可以选择半精度,从而进一步提升性能。
除矩阵乘法以外的6个kernel,大部分都是对矩阵乘的结果进行一些element-wise的操作。输入矩阵的大小,跟4个参数有关,batch size,句子长度,attention的head数量以及每个head的维度。针对不同的应用场景,参数大小可能极为不同。比如在线问答类的场景,batch size可能为会很小,通常为1。而广告推荐或者搜索类的场景,batch size通常跟候选集大小有关,一般会是几百的规模。这样,输入矩阵的行数变化范围可能是几十到上千。因此,我们需要针对不同的情况,动态的调整kernel launch时的配置参数(grid和block的大小),甚至要针对同一个功能实现多个不同版本的kernel函数,例如,SoftMax的计算就有两个不同的实现版本。
针对半精度FP16,我们对各个kernel也进行了相应优化。首先,在kernel的实现中,将输入的half指针转成half2类型,并使用了half2相关的数学函数。这样不仅仅可以达到2倍于half的访存带宽和计算吞吐,还可以极大地减少指令的发射数量。其次,在SoftMax以及Layer Normalization的操作中,为防止求和溢出,将数据以half2的形式读入后,会转成float2类型,来做求和计算。
除上述优化之外,Faster Transformer还优化了前向计算中耗时较高的GELU激活函数,Layer Normalization以及SoftMax等操作。比如利用warp shuffle实现高效的矩阵按行求和操作, 将1/sqrtf计算替换为rsqrtf函数,以及power (x, 3.0) 替换为x * x * x等。总之,我们针对Transformer进行了各种优化以保证它的高效执行。
结论
Faster Transformer是一个开源的高效Transformer实现,相比TensorFlow XLA 可以带来1.5-2x的提速。Faster Transformer对外提供C++ API, TensorFlow OP,以及TensorRT Plugin三种接口。对每种接口的调用方式,我们提供了完整的示例,方便用户集成。
[1] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. “Attention Is All You Need.” ArXiv:1706.03762 [Cs], June 12, 2017. http://arxiv.org/abs/1706.03762.
[2] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” ArXiv:1810.04805 [Cs], October 10, 2018. http://arxiv.org/abs/1810.04805.
[3] Yang, Zhilin, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. “XLNet: Generalized Autoregressive Pretraining for Language Understanding.” ArXiv:1906.08237 [Cs], June 19, 2019. http://arxiv.org/abs/1906.08237.
[4] TensorRT: https://developer.nvidia.com/tensorrt
[5] Turing T4 GPU, more information: https://www.nvidia.com/en-us/data-center/tesla-t4/
[6] Volta V100 GPU, more information: https://www.nvidia.com/en-us/data-center/tesla-v100/
[7] Pascal P4 GPU, more information: https://www.nvidia.com/en-us/deep-learning-ai/solutions/inference-platform/hpc/











