
RAPIDS 0.7现已上线!
2019-05-29 09:00
 分享到微信
分享到微信
 分享到微博
分享到微博
RAPIDS 0.7现已上线! RAPIDS在诸多方面进行了改进,适用范围扩大到了前所未有的程度,XGBoost现在可以更加容易的在多个GPU上使用。
XGBoost的重大提升
借助于RAPIDS dask-cudf和dask-xgboost的改进,XGBoost比以往更易应用于多GPU之上,希望这些强大的工具能够为更多数据科学家所用。与所有RAPIDS一样,这些库通过conda套件,以及NGC和DockerHub上的容器提供。值得指出的是,XGBoost现支持各种目标函数。为确保不出现混淆,针对XGBoost的所有RAPIDS修改和改进都将被上传至DMLC/XGBoost。虽然RAPIDS为XGBoost提供了conda套件,但这只是为了方便早期采用者。NVIDIA坚持对XGBoost库和众多开源项目提供支持并给予回馈。提升Dask-XGBoost的功能还需要时间;还请持续关注相关最新动态。
RAPIDS步入云端
让人们能够轻松地使用RAPIDS始终是我们的重中之重。首先要提的是针对RAPIDS的应用培训和推广。谷歌云平台(GCP)对RAPIDS的推广做出了巨大支持,GCP在GTC美国期间慷慨地捐赠了计算实例,还与参会者们分享了如何使用RAPIDS建立模型并预测“黑五”促销的需求。然而这还只是开始,更大的喜讯还在后面。
谷歌Colab是类似Jupyter-Notebook的托管服务,最近其已开始提供NVIDIA T4 GPU。这使RAPIDS能够集成至谷歌Colab中,如今你可以免费试用RAPIDS了!谷歌Colab非常适合用来试用完整的RAPIDS套件,并对单GPU工作负载进行实验。
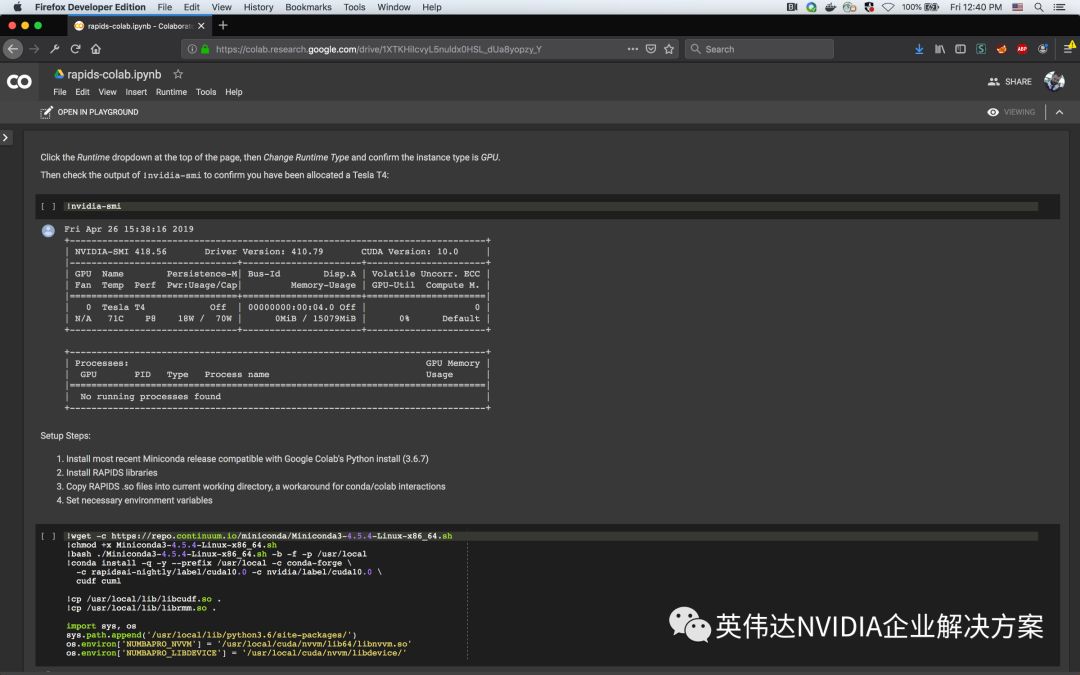
最后,谷歌的另一个里程碑:近期,谷歌Dataproc在其一期主题为《Cloud OnAir:Cloud Dataproc中的全新开源工具》的研讨会中宣布RAPIDS集成会成为全新的初始设定。目前尚处于早期测试阶段,Dataproc用户可在谷歌环境中轻松快速地配置NVIDIA GPU集群,以大规模试用RAPIDS。有了Dataproc,就能够利用带有dask-XGboost的RAPIDS,使用多GPU和GPU节点集群来针对更大的问题进行训练。
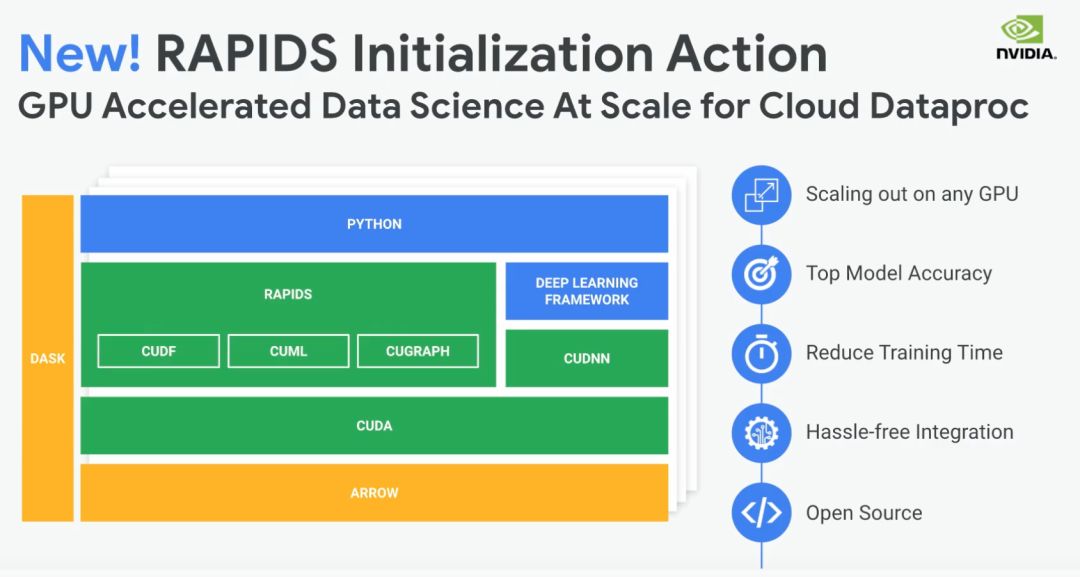
总之,RAPIDS现在已步入云端——在Azure、Databricks以及整个谷歌平台上,包括:GCP DL VM、Colab、Dataproc和KubeFlow。此外,对于AWS和NGC-Ready的其他云,你可使用NGC容器快速试用RAPIDS。如此多处可供使用!
新功能和改进
RAPIDS cuDF库0.7让很多事情都变得更简易了。现在有系列化的累积和产品、min和max功能。事实上,我们对C++的归约操作进行了一系列全面大检查,修复了几项错误,添加了null支持,提升了数据类型灵活性,并增加了libcudf的聚合覆盖率。我们还添加了DataFrame.pop(),这样在一行中就能获取标签列和数据矩阵。为重塑数据,我们添加了多索引支持,包括“join”和“groupby”功能,以及DataFrame.melt()方法。min和max方法现在支持datetime列。另外还有一处改进,就是更多cuDF函数可支持null/NA数据。 cuDF每一新版本都更加完善,我们期待着0.8的发布。还有一些令人兴奋的,就是滚动窗口功能和GPU加速的to_csv()函数。
在RAPIDS cuML库中,我们在Python端添加了两个新方法。一个是全新的:适用于套索和弹性网络回归的坐标下降求解器。另一个是一项很大的改进:一个完全基于我们的机器学习原语重写的的单GPU版本的k-均值。我们在幕后做了巨大努力以完善代码,并添加了C++方法,如拟牛顿(Quasi-Newtonian)求解器和随机森林(Random Forests),其将在日后新版本中以Python语言公开。
cuGraph会持续改进并完善其代码库,注重匹配NetworkX API。对0.7版本的最新分析是:(1)杰卡德相似系数(Jaccard similarity)的增强,使任何顶点对之间都能进行比较;(2)额外的重叠系数(Overlap Coefficient)作为Jaccard的替代;(3)三角形计数(Triangle Counting);(4)子图提取(Subgraph Extraction);(5)和重新编号(Renumbering)。
最后,我们还做到了你想要的:更完善的错误处理!这需要对底层libcudf库重写Python绑定以使用Cython,因此现在低级错误能够干净利落地传递至最终用户以进行更好的诊断。0.7版本向着完全重写绑定迈出了第一步,我们将在后续版本中解决各相应问题。
安装“两原则”
从0.7版本开始,在可预见的未来,我们仅支持两种安装格式:conda和源安装。经深思熟虑后,我们决定不支持PIP。
如此之低的入门门槛
随着RAPIDS 0.7版本的推出,为支持不断扩大的社区,我们将在GitHub上分享我们新的Notebooks Extended repo。你可以视其为RAPIDS社区的笔记本,它为数据从业者提供一个发展技能和教授他人所学知识的地方。我们希望Notebooks Extended将成为获取最新提示和技巧的好去处,并让RAPIDS新手们能够不断成长并熟练掌握RAPIDS。
财经新闻中的RAPIDS!
前不久,NVIDIA打破了STAC A3基准测试的此前最高分,创造了新纪录,在这项纪录的背后,RAPIDS可谓是功不可没。STAC A3是衡量回测性能的指标,其在金融服务领域至关重要(了解详细信息,请阅读“推荐阅读”)。
使用表列数据进行深度学习
采用PyTorch的RAPIDS

RAPIDS使得在深度学习中使用表列数据成为可能。在最近的一篇文章中,我们探讨了像XGboost这样的传统机器学习方法与深度学习DNN的性能比较。对于RAPIDS,首次涉足深度学习可谓重要一步,这表明我们能够通过DNN,采用相当简单的模型实现与XGboost类似的性能。
期待0.8,展望更多
针对接下来的0.8版本,我们正致力于发布随机森林的单GPU实施,此外我们也在为0.9版本的多节点、多GPU k-均值和随机森林奠定基础。我们还正在与OpenUCX社区合作,将UCX集成至Dask中。这目前进展顺利,最快将在0.8版本中实现,0.9和0.10版本还会有更多优化和支持。
如果你一直在考虑尝试使用RAPIDS,通过谷歌Colab,几秒钟内就能着手开始。对于老用户,也可以通过很多方式尝试最新版本,文档也有所改进,并且有许多入门笔记本能让你能够了解RAPIDS中的许多新功能。我们很高兴有你加入社区。如果你喜欢RAPIDS,请在GitHub上给我们标星,如有任何问题或功能请求,也请提交GitHub问题,这将有助于其进一步完善。











