
Jetson Xavier在图像识别与智能诊断中的应用测评
2019-05-23 09:00
 分享到微信
分享到微信
 分享到微博
分享到微博
(本文已获得作者授权发布)作者李丹丹,毕业于哈尔滨工业大学工业自动化仪表专业,现就职于哈尔滨工业大学航天学院。博士期间从事超声图像三维重建方向的研究,在边缘检测、骨架抽取、弹性配准、形态学重建等多个方面都提出了算法上的改进。目前主要研究方向是在嵌入式GPU平台上,进行基于图像的人工智能的应用及算法研究。
Jetson Xavier是NVIDIA瞄准机器人和工业自动化等AI用例推出的嵌入式开发平台,这是一款功能齐全的小型计算系统,Xavier芯片本身设计为完整的商业现货(COTS)系统,整个平台的尺寸不超过105mm x105mm。
NVIDIA在这款开发板上大方的配上了自研的Carmel架构8核64位CPU和Volta架构512 CUDA处理器GPU这两大杀器,同时还拥有16GB 256位LPDDR4X的CPU和GPU公用的存储器,既是显存也是内存。Xavier的Volta架构GPU内部有512个CUDA核心,其单精度浮点运算性能为2.8Tflops,双精度为1.4Tflops,特别的是Xavier还集成了Tensor Core,其8bit运算性能为22.6Tops,16bit运算性能为11.3Tops。
Xavier的核心竞争力是其机器推理性能,除了CPU和GPU,Xavier内还设计有全新的DLA(Deep Learning Accelerator,深度学习加速器)和PVA(Programmable Vision Accelerator,可编程视觉加速器)单元,Volta GPU与DLA核心相结合,在低功耗平台上构筑了强大的处理能力。为了展示该系统的机器学习推理能力,NVIDIA为Jetson Xavier AGX平台提供了大量软件开发套件以及手动调整框架,特别是TensorRT框架,预先为开发者做了大量繁重的准备工作,使他们能充分利用GPU中的Tensor Core和DLA单元。
本文作者长期从事基于医学图像的智能识别与诊断的研究工作,结合具体的研究内容,对基于图像的智能诊断在Xavier上的部署结果做了相应的测试工作,其性能是令人惊艳的。
和所有的基于图像的AI应用一样,基于医学图像的智能识别与诊断首先需要完成图像采集工作。如果要形成一个成熟的产品,最理想的方式就是为Xavier定制一款具备多种图像采集接口的底板,这种方式其体积和整体稳定性都有很大的优势。但这种方式通常成本较高且需要定制周期,对于研究阶段的初学者们在Xavier上推荐两种图像采集方式。
第一种是通过USB3.0接口接入图像采集卡,根据接口支持种类的多少,这些采集卡价格在几百元到几千元不等,根据实际需要可以自行选择,注意确认该采集卡支持Ubuntu系统即可。虽然Jetson平台配备的不是通用的Ubuntu系统,而是针对Tegra核心定制的L4T(Linux for Tegra)系统,但在USB3.0接口的图像采集卡接入这个方向上,实际使用过程中并未发现过不兼容的现象。
第二种方式是通过PCIE接口接入图像采集卡。Xavier计算模块和载板之间通过699Pin的夹层连接器连接,目前已经支持PCIe4.0规范,这也是NVIDIA的第一款PCIe 4.0产品。和USB3.0接入方式相比,PCIE接入方式具有更稳定的速度,并且在多接口支持的情况下,相比USB3.0的采集卡具有价格上的优势。但是使用PCIE采集卡时一般无法使用该卡在Linux平台下的通用驱动程序,必须为L4T平台定制驱动,这需要厂家提供较好的技术支持。
不论是USB3.0接口的图像采集卡,还是PCIE接口的图像采集卡,接入系统之后在系统中都会虚拟为一个摄像头设备,可以在Terminal终端通过“ls /dev/video*”命令确认设备的接入,也可以通过通用的摄像头交互程序完成相应的读取操作。
在摄像头交互程序中也有两个选择。一个是使用Jetson平台提供的OpenCV4Tegra开发包,这种方式可以使用常见的OpenCV摄像头交互接口,可以很容易找到大量的范例代码,易于上手与维护。另外一个选择是使用基于pipeline的GStreamer框架中提供的摄像头交互接口,这种方式与CUDA编程结合的更紧密,可以提高摄像头交互程序的效率,但相对来说编程入手门槛较高。如果处理对象的数据并发量不是很大,也没有对于高频视频的实时处理场景,OpenCV接口就可以满足需求了。
获取到摄像头的图像数据之后,就可以对其使用后续的机器学习或者深度学习算法进行处理与分析了,在这一过程中,Xavier的优势在于其16G的超大“显存”,以及Jetson平台提供的高速推理引擎TensorRT。TensorRT使用CUDA C进行编程,在GPU上做推理的计算。针对一个训练好的模型,TensorRT可以通过网络层及张量合并、低精度运算、内核自动调整、动态张量内存等操作,对计算流图进行优化,实现推理加速。在实际使用中,我们在医学图像数据集上,在Xavier上对于几种较常用的深度学习分类及分割模型进行了测试,TensorRT加速前和加速后的实测结果如下图所示。
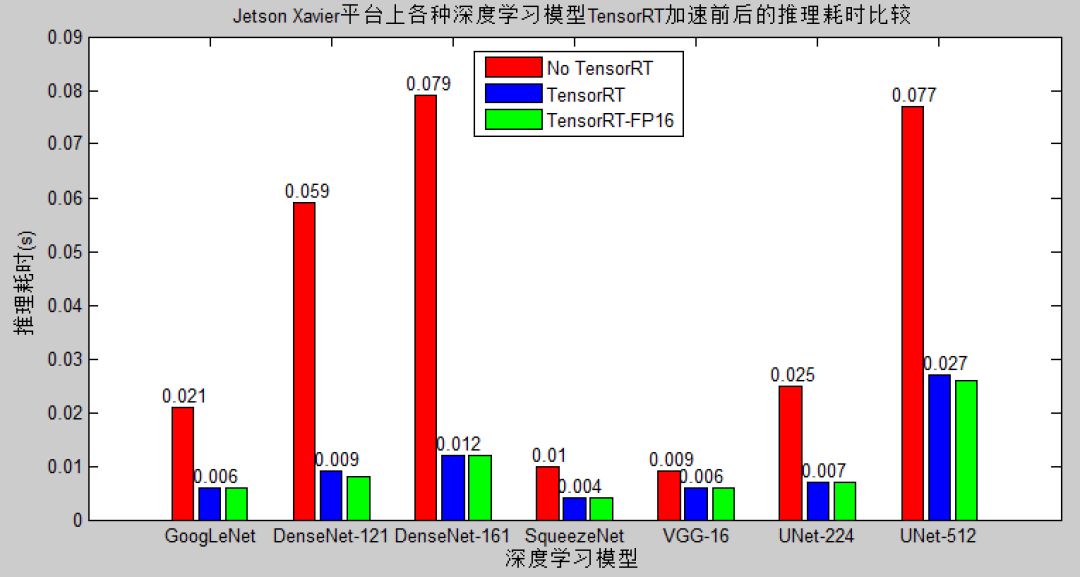
从上图可以看出,模型越复杂,TensorRT的加速性能越明显。对于面向手机应用的浅层模型SqueezeNet,TensorRT的加速性能大概是两倍,而对于结构较为复杂的161层的DenseNet模型,TensorRT展现出了惊人的约为八倍的加速性能,这使得基于复杂模型的实时提供了更多的可能性。由于Xavier不支持int8模式的TensorRT加速推理,我们只测试了FP32和FP16精度下的TensorRT加速,也许是因为仅做了单张图片的推理测试,在我们的测试中并未发现FP16精度有明显的性能提升,但值得一提的是,FP16精度也并未对推理准确度带来明显的降低,准确度偏差一般在0.5%以内,对于大型并发处理需求还是推荐尝试一下。
针对当前NVIDIA已经推出的多种Jetson平台——Jetson TX2、Jetson Xavier和Jetson Nano,我们也对TensorRT加速之后的推理性能做了一下横向对比测试,实测结果如下图所示。
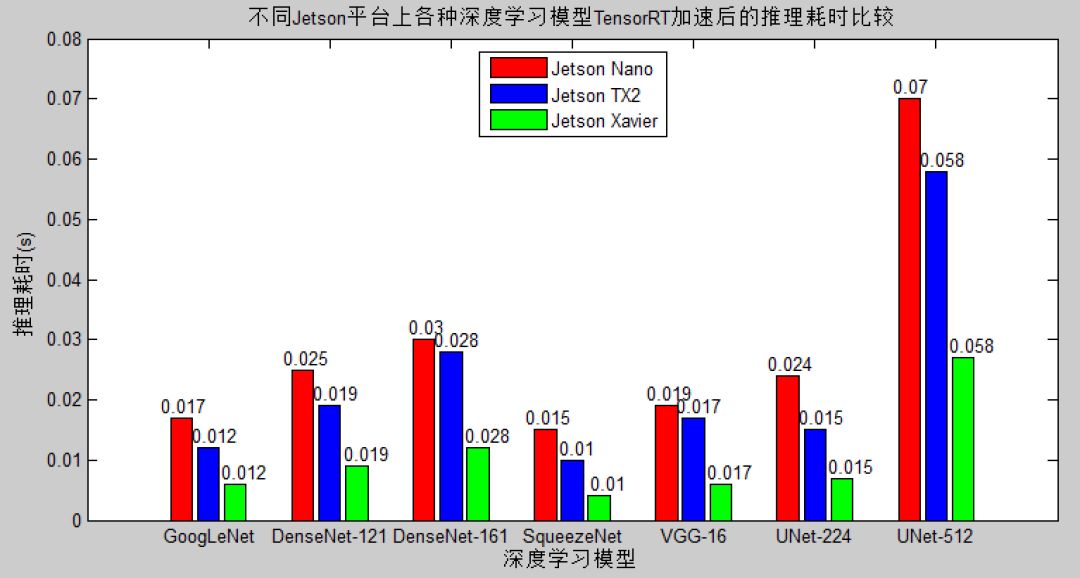
从测评结果可以看出,Jetson Xavier平台在同系列产品中也是性能表现最为优异的一款,如果对于推理性能要求较高且预算宽裕,Jetson Xavier是人工智能应用在终端部署的最佳选择。
这说明,无论是否用到了GPU加速,Xavier的性能表现都很出色。目前还有很多视觉算法仍处于非常传统的阶段,无法通过GPU或Tensor Core加速,只能依靠强大的CPU来硬扛,在这些场景下,只有Xavier这样拥有高性能CPU的芯片才能发挥出更好的性能。
虽然Jetson AGX Xavier开发套件价格高达10499元,但对于那些需要大量视觉处理,或需要实现工业自动化的公司而言,Jetson AGX Xavier绝对是比其他平台更容易接受且更开放的选择。











